VQ: Vector Quantization
چندی سازی برداریVQ: Vector Quantization
چندی سازی برداریفشرده سازی تصویر
فشرده سازی تصویر عملیاتی است که ضمن حفظ اطلاعات تصویر از حجم آن کاسته و زمان و حافظه کمتری صرف ذخیره سازی و انتقال داده ها می گردد همچنین عملیاتی فشرده سازی تصویر قسمتی از فشرده سازی اطلاعات می باشد و کاربرد آن در تصاویر دیجیتال می باشد که هدف آن کاهش افزونگی می باشدو به دو صورت می باشد
1. با اتلاف( lossy): در عملیات فشرده سازی مقداری از داده ها از بین می روند و بعد از بازیابی تصویر به دست آمده با تصویر اصلی فرق می کند
2. بدون اتلاف(lossless) : در عملیات فشرده سازی هیچ داده ای از بین نمی رود از برای بعضی تصاویر مانند نقشه های فنی و آیکونها استفاده می شود زیرا فشرده سازی با اتلاف مخصوصا زمانی که برای نرخ بیت های پایین استفاده می شود به کیفیت تصویر لطمه وارد می کند. همچنین ممکن است برای تصاویر با ارزش مثل تصاویر پزشکی یا تصاویر اسکن شده برای بایگانی ترجیح داده شوند روشهای بدون اتلاف عبارتند از run-length encoding که یکی از امکانات BMP، TGA، TIFF می باشد
الگوریتمهای فشرده سازی بدون اتلاف
دسته بندی کدینگ بدون اتلاف
1. مبتنی بر آنتروپی
2. مبتنی بر واژه نامه
3. سایر
1- کدینگ مبتنی بر آنتروپی
در آن به ازای هر سمبول موجود در داده یک کلمه رمز(word code) منحصر به مفرد در نظر گرفته می شود. طبق نظریه شانون بهترین طول کد برای هر سمبول طبق رابطه زیر می باشدکه pi در آن احتمال رخداد سمبول iام می باشد.


1. تکنیک کدگذاری هافمن(Huffman):
در این روش از تکنیک جایگزینی کد یکسانی برای نمادهایی با کدهای نامحدود است، که به تکرار وقوع یک نماد در متن بستگی دارد و در آن هر نماد در مجموعه ای که کدها از آن استخراج می شوند ارزش یکسانی با بقیه دارد. ارزش کد کلمه ای که طول آن N است برابر N خواهد بود بدون در نظر گرفتن تعداد اقام 1 و 0 . هدف این تکنیک مینیمم کردن طول کد ایجاد شده می باشد بدین معنی که تعداد بیتهای استفاده شده در آن کمترین باشد و در آن کد پیشوندی رعایت شده باشد. کد پیشوندی نوع خاصی از کد با طول متغییر می باشد که کد یک کاراکتر، آغاز کد کاراکتر دیگر نمی باشد. به طور مثال اگر کد حرف"a" را 01 قرار دهیم آنگاه کد حرف "b" نباید 011 باشد با یک مثال این روش را توضیح می دهیم
مثال
(a:16 , b:5 , c:12 ,:d:17, e:10 , f:25)
اعداد مقابل هر حرف تعداد تکرار حرف مورد نظر می باشد
ابتدا آنها از بر حسب تعداد تکرار از کوچک به بزرگ مرتبط کنید

در واقع یک صف اولیت ایجاد می کنیم در ابتدا دو عدد کوچکتر را انتخاب می کنیم و آنها را با یکدیگر جمع می کنیم در مکان مناسب در صف قرار می دهیم که در بین 12 و 16 قرار می گیرد
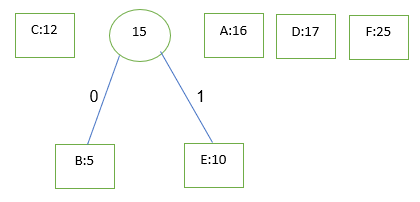
حال دو عنصر کوچک صف که 12 و 15 می باشند را مجددا انتخاب می کنیم
وعملیات بالا را مجددا تکرا ر می کنیم
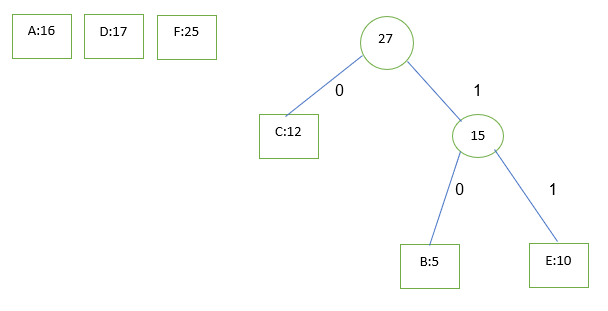
حال 16 و 17 را انتخاب می کنیم و عملیات را تکرار می کنیم

حال 27 و 25 را انتخاب می کنیم و مراحل را تکرار می کنیم
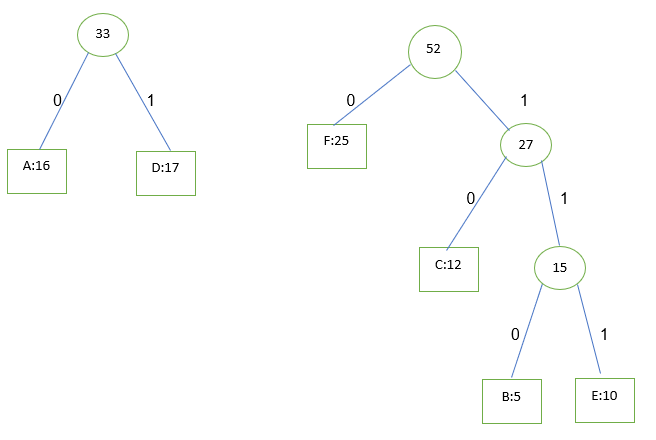
حال 52 و 33 را انتخاب می کنیم و مراحل را مچددا تکرار می کنیم
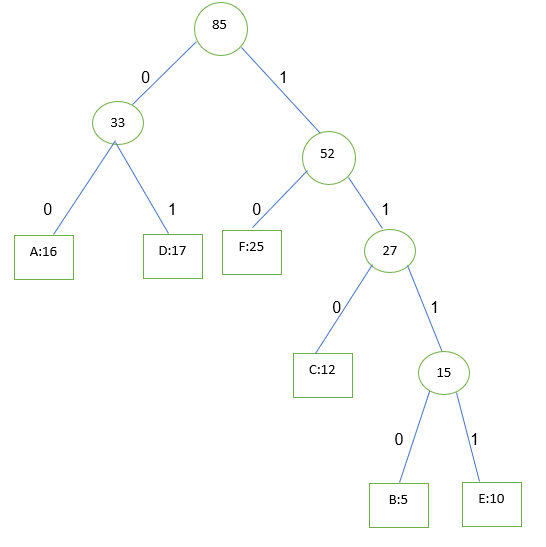
حال اعداد را از ریشه به سمت هر نود خوانده تا کد حرف مورد نظر مشخص کردد همانطور که می بینید کد حروف با تکرار بیشتر کوچکتر می باشد
A:00 d:01 f:10 c:110 b:1110 e:1111
تعداد بیت مورد نیاز
16*2+2*17+2*25+3*12+4*5+4*10=32+34+50+36+20+40=212
برای رمزگشایی هر فایل یک کتاب رمز (code book) در ابتدای آن وجود دارد که مشخص می کند هر دنباله بیت مربوط به چه سمبولی می باشد.
بهترین حالت ممکن برای کاهش افزونگی در این کد قابل اثبات می باشد، بدین معنا که میانگین بیت های متناظر با سمبول ها از 1 + ƞ کمتر می باشد.
2. کد هافمن توسعه یافته
زمانی که احتمال رخداد سمبول ها (pi) بزرگ باشد . در واقع تعداد بیت های لازم
برای سمبول ها بر اساس نظریه اطلاعات نزدیک به صفر باشد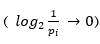 ) الگوریتم هافمن کارآمد نخواهد بود و در این حالت
از روش کد هافمن توسعه یافته استفاده می شود. در این روش به جای آنکه به ازای هر
سمبول یک کلمه رمز استفاده گردد برای ترکیبی از سمبول ها معادل دودویی در نظر
گرفته می شود.
) الگوریتم هافمن کارآمد نخواهد بود و در این حالت
از روش کد هافمن توسعه یافته استفاده می شود. در این روش به جای آنکه به ازای هر
سمبول یک کلمه رمز استفاده گردد برای ترکیبی از سمبول ها معادل دودویی در نظر
گرفته می شود.
به عنوان مثال اگر برای الفبای S ={s1,s2,…,sn} الفبای توسعه یافته آن 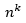 الفبا خواهد داشت. روش هافمن توسعه یافته هرچند نسبت به روش هافمن
معمولی بهبودهایی یافته است اما این مقدار چشمگیر نمی باشد. ولی اگر مقدار kبزرگ باشد آنگاه تعداد الفبای
توسعه یافته بسیار زیاد خواهد شد و در نتیجه جدول سمبولها حجیم خواهد شد.
الفبا خواهد داشت. روش هافمن توسعه یافته هرچند نسبت به روش هافمن
معمولی بهبودهایی یافته است اما این مقدار چشمگیر نمی باشد. ولی اگر مقدار kبزرگ باشد آنگاه تعداد الفبای
توسعه یافته بسیار زیاد خواهد شد و در نتیجه جدول سمبولها حجیم خواهد شد.
3. کد هافمن تطبیقی
در این روش ابتدا یک درخت ایستا بر اساس داده های موجود ایجاد می گردد و سپس با دریافت اطلاعات بیشتر از سمت فرستنده ، درخت به صورت پویا به روز رسانی می گردد.
|
DECODER --------------- Initial_code(); While not EOF { Decode(c); Output (c); Update_tree(c); } |
ENCODER ----------------- Initial code (); While not EOF { Get (c); Encode©; Update_tree(c); }
|
شرط لازم جهت استفاده از چنین روشی استفاده از درخت اولیه یکسان (Initial_code) و الگوریتم بروزرسانی (update_tree) مشابه در گیرنده و فرستنده می باشد.
توضیح الگوریتم
 گره ها به ترتیب از چپ به راست و ایین به بالا شماره گذاری شده اند و اعداد
نوشته شده در پرانتزها نشان دهنده تعداد سمبول ها می باشند.
گره ها به ترتیب از چپ به راست و ایین به بالا شماره گذاری شده اند و اعداد
نوشته شده در پرانتزها نشان دهنده تعداد سمبول ها می باشند.-
ویژگی sibling باید همیشه حفظ
گردد، بدین معنی که همه گره ها باید به صورت افزایش تعداد مرتب شده باشند و در غیر
این صورت روال تعویض (swap) فراخوانی می گردد و ترتیب گره ها به روزرسانی می شود.
-
در هنگام اجرای روال تعویض گره والدی که تعداد آن کمتر است با گره ای که تعداد
آن بیشتر است تعویض می گردد.
4. کدینگ حسابی(Arithmetic)
روش جدیدتری می باشد که معمولا نتایج بهتری در مقایسه با کد هافمن دارد. در کد هافمن به ازای هر سمبول یک کلمه رمز اختصاص می یابد که تعداد صحیحی از بیت ها برای آن در نظر گرفته می شود، در صورتی که در کدینگ حسابی همه داده ها با یک عدد رمز گذاری می گردد. به ازای هر سمبول با با توجه به فرکانس تکرار آن در داده یک احتمال رخداد و یک بازه متناظر با آن در نظر گرفته می شود، به طور مثال برای کلمه <<ایران>> احتمال رخداد و بازه متناظر هر حرف به صورت زیر خواهد بود.
|
ن |
ر |
ی |
ا |
حرف |
|
0.2 |
0.2 |
0.2 |
0.4 |
تعداد |
|
)0.8،1[ |
)0.6،0.8[ |
)0.4،0.6[ |
)0،0.4[ |
بازه |
معادل رمز شده هر داده با عددی در بازه (0،1[ نشان داده می شود. این بازه بر اساس ترتیب سمبول ها و بازه متناظر با هر کدام مشخص می گردد و با افزایش طول سمبول بازه نیز محدودتد خواهد شد. به عنوان مثال برای کلمه <<این>> داریم:
· برای حرف <<ا>> بازه (0،0.4[ را انتخاب می کنیم
· بازه (0،0.4[ را مجددا بر اساس بازه های هر حرف تقسیم بندی می کنیم
· الگوریتم را تا آخرین حرف ادامه می دهیم.

· در نهایت بازه معادل برای کلمه <<این>> (0.224،0.24[ خواهد بود که برای کد کردن داده ابتدای بازه در نظر گرفته می شود.
· برای ذخیره سازی یا ارسال داده تلاش می شود از بازه مورد نظر کوتاه ترین دنباله اعداد استخراج گردد به عنوان مثال معدل دودویی 0.224 و 0.24 به ترتیب 0.11100000 و 0.10111 می باشد و در نتیجه کافی است برای ذخیره کلمه <<این>> از 5 بیت استفاده کرد.
· در این تکنیک فشرده سازی تضمین نمی گردد و حتی ممکن است افزایش حجم ذخییره سازی هم رخ دهد
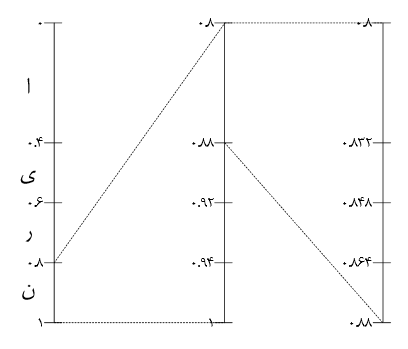
· در فرایند رمرگشایی نیز عکس عملیات فوق انجام می سود مثلا برای 0.87 خواهیم داشت :
· از آنجا که 0.87 در بازه (0.8،1[ می باشد حرف <<ن>> را انتخاب می کنیم.
· همچنین چون 0.87 در بازه (0.8،088[ می باشد حرف <<ا>> را انتخاب می کنیم.
· در نهایت با ادامه این فرآیند به کلمه <<نان>> می رسیم
5. کدینگ طول متغییر)(VLE)(Variable-Length Encoding
در این کدینگ از الگوریتم شانون -فانو استفاده گردیده است.
· مرتب سازی علائم بر اساس فرکانس تکرار
· به صورت بازگشتی دنباله علائم به دو بخش تقسیم می گردند به صورتی که مجموع فرکانسهای تکرار برای هر دو بخش یکسان گردد تا زمانی که هر بخش شامل یک علامت گردد.
به عنوان مثال کلمه ایرانیان را در نظر بگیرید
|
حرف |
ا |
ی |
ن |
ر |
|
تعداد |
3 |
2 |
2 |
1 |
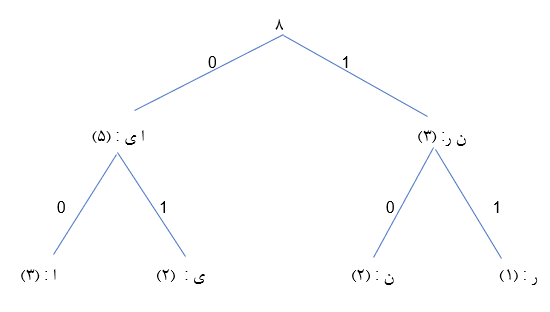
در هر شاخه تقسیم بندی به گونه ای انجام می شود که مجموع تکرار حروف در هر زیر شاخه آنقدر ادامه می دهیم تا تنها یک علامت باقی بماند.
برای هر زیر شاخه بیت 0 و 1 را اختصاص می دهیم و مسیر رسیدن هر علامت در واقع تعیین کننده علامت خواهد بود مثلا 10 برای حرف"ن".
|
حرف |
تعداد |
کد |
تعداد بیت استفاده شده |
|
ا |
3 |
00 |
6 |
|
ی |
2 |
01 |
4 |
|
ن |
2 |
10 |
4 |
|
ر |
1 |
11 |
2 |
|
مجموع تعداد بیت ها : 16 |
|||
اگر می خواستیم این حروف به صورت غیر فشرده ذخیره سازی کنیم باید 8 بیت برای هر کاراکتر در نظر گرفته می شد که در کل به 64 بیت نیاز بود.
در این روش همیشه درخت یکتا وجود ندارد به طور مثال در کلمه ایرانیان می توان درخت زیر را نیز رسم کرد

کدینگ مبتنی بر واژه نامه
در آن مجموعه ای از زیر رشته ها در یک ساختمان داده به نام واژه نامه ذخیره می گردد و رمزکننده هر زمان الگویی که با یکی مخل های واژه نامه منطبق یابد آن را با کد معادلواژه نامه جایگزین می کند.

کدینگ Run-Length(RLE)
منبع بدون حافظه : منبعی است که در آن اطلاعات (سمبول ها و ...) به طور مستقل پراکنده شده اند، در واقع مقدار هر سمبول به سمبول های قبلی وابستگی ندارد.
کدینگ Run-Length منبع اطلاعات را به شکل با حافظه در نظر می گیرد. در واقع یک شکل فشرده سازی از داده ها می باشد و بدین طریق عمل می کند که داده ای یکسان پشت سر هم به صورت مقادیر تکی و تعداد تکرارشان ذخیره می گردند. اگر چه آسان است و به راحتی قابل درک می باشد ولی هنوز کارآیی چندانی ندارد.

تکنیک LZW()Lempel-Ziv-Welch
از کلمه رمز با طول ثابت برای بازنمایی دنباله ای از سمبول ها که طول آنها متغییر می باشد و معمولا در منبع موجود هستند استفاده می گردد. مانند کلمات موجود در یک متن.
رمز کننده (encoder) و رمزگشا(decoder) در LZW به صورت پویا واژه نامه مشابهی را در زمان دریافت اطلاعات ایجاد می کنند. در آن مدخل های واژه نامه با گذشت زمان طولانی تر می شوند. این الگوریتم در برنامه های فشرده سازی تصاویر GIF مورد استفاده قرار می گیرد که به طور میانگین حجم تصویر را به ک سوم کاهش می دهند.
شبه کد الگوریتم فشده سازی LZW
BEGIN
S = next input character;
While not EOF
{
C= next input character;
If s + c exists in the dictionary
s = s + c;
else
{
output the code for s;
add string s + c to the dictionary with a new code;
s = c;
}
}
output the code for s;
END
مثال:
برای فشرده سازی دنباله ای از کلمات از یک واژه نامه ساده شامل 3 کاراکتر استفاده می کنیم
|
کد رشته(code string) |
|
|
A |
1 |
|
B |
2 |
|
C |
3 |
حال اگر ورودی زیر به رمز کننده داده شود:ABABBABCABABBA خروجی به صورت کدهای124523461 خواهد بود در روش به جای 14 کاراکتر 9 کد ارسال می شود لذا نرخ فشرده سازی برابر است با 14.9=1.56 .
|
|
string |
code |
output |
C |
S |
|
|
A |
1 |
|
|
|
|
|
B |
2 |
|
|
|
|
|
C |
3 |
|
|
|
|
1 |
AB |
4 |
1 |
B |
A |
|
2 |
BA |
5 |
2 |
A |
B |
|
3 |
|
|
|
B |
A |
|
4 |
ABB |
6 |
4 |
B |
AB |
|
5 |
|
|
|
A |
B |
|
6 |
BAB |
7 |
5 |
B |
BA |
|
7 |
BC |
8 |
2 |
C |
B |
|
8 |
CA |
9 |
3 |
A |
C |
|
9 |
|
|
|
B |
A |
|
10 |
ABA |
10 |
4 |
A |
AB |
|
11 |
|
|
|
B |
A |
|
12 |
|
|
|
B |
AB |
شبه کد رمزگشایی
BEGIN
S=NIL;
While not EOF
{
K = next input code;
entry = dictionary entry for k;
output entry;
if (s != NIL)
add string s + entry [0] to dictionary with a new code;
s = entry;
}
END
برای ورودی زیر در رمزگشا:
124523461
خروچی به صورت زیر خواهد بود:
ABABBABCABABBA
|
string |
code |
output |
C |
S |
|
A |
1 |
|
|
|
|
B |
2 |
|
|
|
|
C |
3 |
|
|
|
|
|
|
A |
1 |
NIL |
|
AB |
4 |
B |
2 |
A |
|
BA |
5 |
AB |
4 |
B |
|
ABB |
6 |
BA |
5 |
AB |
|
BAB |
7 |
B |
2 |
BA |
|
BC |
8 |
C |
3 |
B |
|
ABA |
10 |
ABB |
6 |
AB |
|
ABBA |
11 |
A |
1 |
ABB |
|
|
|
|
EOF |
A |
در کاربردهای واقعی معمولا دامنه مشخصی برای طول کد فشرده سازی در نظر گرفته می شود [Lo Lmax]. اندازه واژه نامه در ابتدا خواهد بود و حداکثر تا می تواند افزایش یابد. در این روش زمانی که طول کد به Lmax می رسد از روش های خالی سازی حافظه (flushed) استفاده می گردد.
سایر روشهای کدینگ
روشهای مبتنی بر آنتروپی و واژه نامه معمولا برای کاربردهای عمومی تر و برای هر نوع داده استفاده می شوند اما روشهایی که در تدامه توضیح داده خواهد شد در فشرده سازی چندرسانه ای کاربرد بیشتری دارند.

کدینگ تفاضلی
داده های چند رسانه ای دارای وابستگی بین داده های متوالی می باشند به عنوانمثال در تصویر رنگ یک پیکسل بسیار شبیه به رنگ پیکسل های همسایه می باشد و یا در یک فایل صوتی هر نمونه در زمان بعدی در دنباله حرکت نمونه های قبلی حرکت می کند که به آن افزونگی می گویند(temporal redundancy). در کدینگ تفاضلی یا دلتا (ِDelta encoding) به جای ذخیره تمام داده های یک منبع چند رسانه ای اختلاف بین آنها را ذخیره می کند که موجب می شود تعداد بیت های کمتری برای ذخیره سازی استفاده گردد.
کدینگ تفاضلی در رسانه های نوشتاری
به عنوان مثال در زمینه وب، کدینگ تفاضلی تحت عنوان RFC3229 در HTTP استفاده گردیده که در آن اختلاف بین دو نسخه متفاوت از صفحات وب ارسال می گردد و دیگر نیازی به ارسال کل داده ها نمی باشد. در این روش به منظور دسترسی به صفحات وب از یک ایستگاه ابتدا سرور با دریافت تغییرات موجود در صفحه و انطباق آن با نسخه ای که ذخیره گردیده اطلاعات را با سرعت بیستری ارسال می کند.مهمترین مزیت این روش کاهش چشمگیر ترافیک اینترنت می باشد.
کدینک تفضلی تصویر:
تصویر تفاضلی ساده d(x , y) برای یک تصویر I(x , y) به صورت زیر تعریف می شود:
d(x , y) = I(x , y) – I(x -1 , y)
یا برایلاپلاسین گسسته دوبعدی داریم:
d(x ; y) =4I(x , y) – I(x , y -1) – I(x , y + 1) – I(x+1 ,y) – I(x -1 , y)
به خاطر افزونگی فضایی موجود در تصاویرمعمولی، تصویر تفاضلی معادل هیستوگرام باریک تری خواهد داشت و بنابراین آنتروپی آن کاهش می یابد. شکل الف و به به ترتیب تصاویر خاکستری و مشتق مرتبط با آن را نشان می دهند و شکل های ج و د به ترتیب هیستوگرام و مشتق آن را نشان می دهد.

کدینگ مبتنی بر پیشگویی
این روش مبتنی بر فشرده سازی آماری می باشد که در آن با استفاده از مجموعه ای از سمبول های قبلی سمبولهای بعدی پیشگویی می گردد. در واقع کدینگ تفاضلی حالت خاصی از کدینگ پیشگویی قلمداد می گردد که در آن تنها از اختلاف سمبول های متوالی استفاده گردیده است. مرتبه مدل پیشگویی تعداد سمبول های قبلی که برای پیشگویی سمبول جدید استفاده می گردد(n) مشخص می شود. از در فشرده سازی تصاویر JPEG بدون اتلاف استفاده شده است.
کدینگ مبتنی برپیشگویی در تصاویر JPEG بدون اتلاف:
در این روش به منظور پیشگویی مقدار هر پیکسل، از ترکیبی از مقادیر حداثر تا 3 همسایه پیکسلی آن استفاده می شود. شکل زیر همسایه های پیکسل X را نشان می دهد و جدول زیر نیز شامل 7 الگوی قابل استفاده برای پیشگویی می باشد.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
B |
C |
|
|
|
|
|
|
|
|
X |
A |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Prediction |
Predictor |
|
A |
P1 |
|
B |
P2 |
|
C |
P3 |
|
A + B - C |
P4 |
|
A + (B - C) / 2 |
P5 |
|
B + (A - C) /2 |
P6 |
|
(A + B) / 2 |
P7 |
رمز کننده مقدار پیشگویی شده را با مقدار واقعی پیکسل در محل X محاسبه می کند و سپس اختلاف موجود را با استفاده از یکی از روشهای بدون اتلاف موجود که معرفی گردیده است مانند کد هافمن رمز می کند. هر یک از مقادیر A, B و C قبل از آنکه برای رمز گشایی X استفاده شوند، رمزگشایی می شوند.
برخی از پسوندهای مطرح در حوزه فشرده سازی بدون اتلاف در تصویر:
• ILBM–(losslessRLEcompressionofAmigaIFFimages)
• JBIG2–(losslessorlossycompressionofB&Wimages)
• JPEG-LS–(lossless/near-losslesscompressionstandard)
• JPEG 2000 – (includes lossless compression method, as provenbySunilKumar,ProfSanDiegoStateUniversity)
• JPEG XR – formerly WMPhoto and HD Photo, includes a losslesscompressionmethod
• PGF–ProgressiveGraphicsFile(losslessorlossycompression)
• PNG –Portable Network Graphics
• TIFF–Tagged ImageFileFormat
• Gifsicle (GPL) –Optimizegiffiles
• Jpegoptim(GPL) –Optimizejpeg files
چندی سازی بردراری(Vector Quantization)
VQ یکی از پرکاربردترین روشها برای فشرده سازی تصاویر می باشد. مکانیزم VQ، کاربردهای زیادی دارد که یکی از آنها فشرده سازی داده ها (متن،صوت،عدد) می باشد. درواقع VQ به سه فاز کد، رمزگذاری بردار و رمزگشایی بردار تقسیم می گردد. در فشرده سازی تصویر، رمزگذار(encoder)، یک آدرس از کلمه کدها ایجاد کرده که به بردار تصویر ورودی نزدیک می باشد. و رمزگشا(decoder) برای بازیابی تصویر از این بردار تصویر استفاده می کند. کتاب کد ، یک عامل کلیدی تاثیرگذار به روی کارایی فرآیند فشرده سازی تصویر می باشد. تولید کتاب کد یکی از فرآیندهای مهم به منظور تشخیص کارایی چندی سازی برداری می باشد. هدف از این کار یافتن بردار کدهایی برای بردارهای آموزشی داده شده می باشد. این کار توسط مینیمم کردن فاصله بین بردارهای آموزشی و بردارکدهای مرتبط به هر کدام انجام می گیرد. در عملیات کدگذاری ابتدا تصویر به بردارهای ورودی (بلاک ها) تقسیم می گردد سپس با کلمه های کد کتاب مقایسه مقایسه می گردد تا نزدیک ترین کلمه کد برای هربردار ورودی پیدا گردد. در واقع اندیس نزدیکترین کلمه کد به بردار تعیین می گردد.البته باید این نکته را در نظر داشت که اندازه کلمه کد از تصویر اصلی خیلی کوچک تر می باشد، که هدف فشرده سازی تصویر می باشد. در فرآیند کدگشایی نیز تصویر توسط کتاب کد مربوطه اش بازیابی می شود.کدگشایی زمانی تکمیل می گردد که تصویر به طور کامل بازیابی گردد. روشهای چندی سازی بردار ی به دو دسته کلاسیک و ممتاهیورستیک تقسیم بندی می گردد. چندی سازی با ساختار درختی، چندی سازی برداری حاصل ضربی و lbg از روشهای کلاسیک هستند.چندی سازی متاهیورستیک شامل الگوریتم های تکاملی و هوش جمعی مانند ژنتیک، بهینه سازی ازدحام ذرات و کرم شب تاب و غیره می باشد. یک دسته بندی دیگر آن را به دو دسته فازییا نرم(fuzzy) و سخت (crisp) تقسیم می شوند که در حالت سخت هر بردار فقط می تواند متعلق به یک خوشه باشد با درجه واحد اعضا در حالی که در حالت فازی هر بردار می تواند متعلق به چند خوشه باشد با درجه های مخلتف اعضا.
کوآنتیزه سازی تصاویر(quantization)
در کوانتیزه سازی تصاویر سطوح نامحدود(پیوسته) شدت روشنایی را به یک محدوده گسسته تبدیل می کنیم. به عبارت دیگر در ابتدا تعداد سطوح روشنایی را کم می کنیم و سپس تصویر را نمایش می دهیم. این روش از ضعف چشم انسان که نمی تواند همه رنگهای واقعی راببیند استفاده کرده است در واقع چشم انسان نمی تواند بین رنگ های خیلی نزدیک به هم تفوت قائل شود. بنابراین لازم نیست همه رنگها نشان دهیم. به منظور حذف رنگهای خیلی شبیه از کوانتیزه سازی استفاده می کنیم. در این روش در واقع بازه ای از رنگه های مشابه را با یک رنگ نشان می دهیم و به این ترتیب تعدادسطوح شده روشنایی را کم می کنیم. هر چه تعداد سطوح روشنایی بیشتر باشد، تصویر نشان داده شده واقعی تر به نظر می رسد و هر چه کمتر باشد تصویر به سمت سیاه وسفید نزدیک خواهد شد.

منابع
فشرده سازی (بدون اتلاف) محمدامین مهرعلیان


























