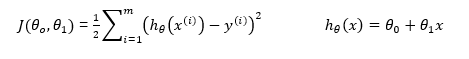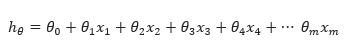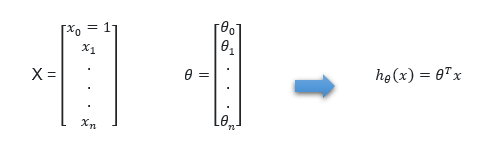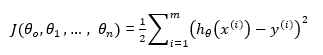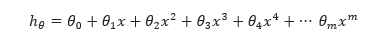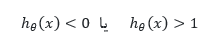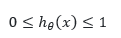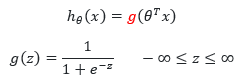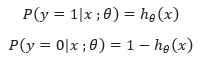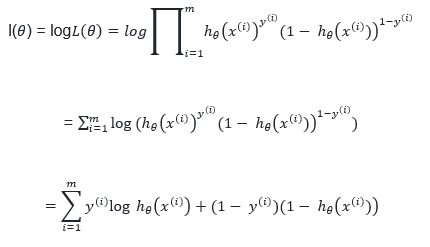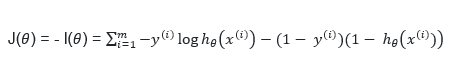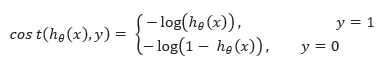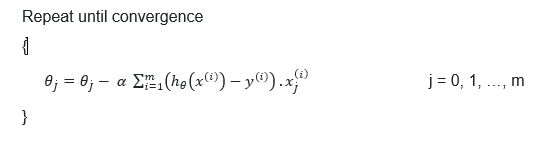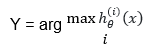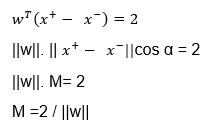VQ: Vector Quantization
چندی سازی برداریVQ: Vector Quantization
چندی سازی برداریچندی سازی بردراری(Vector Quantization)
VQ یکی از پرکاربردترین روشها برای فشرده سازی تصاویر می باشد. مکانیزم VQ، کاربردهای زیادی دارد که یکی از آنها فشرده سازی داده ها (متن،صوت،عدد) می باشد. درواقع VQ به سه فاز کد، رمزگذاری بردار و رمزگشایی بردار تقسیم می گردد. در فشرده سازی تصویر، رمزگذار(encoder)، یک آدرس از کلمه کدها ایجاد کرده که به بردار تصویر ورودی نزدیک می باشد. و رمزگشا(decoder) برای بازیابی تصویر از این بردار تصویر استفاده می کند. کتاب کد ، یک عامل کلیدی تاثیرگذار به روی کارایی فرآیند فشرده سازی تصویر می باشد. تولید کتاب کد یکی از فرآیندهای مهم به منظور تشخیص کارایی چندی سازی برداری می باشد. هدف از این کار یافتن بردار کدهایی برای بردارهای آموزشی داده شده می باشد. این کار توسط مینیمم کردن فاصله بین بردارهای آموزشی و بردارکدهای مرتبط به هر کدام انجام می گیرد. در عملیات کدگذاری ابتدا تصویر به بردارهای ورودی (بلاک ها) تقسیم می گردد سپس با کلمه های کد کتاب مقایسه مقایسه می گردد تا نزدیک ترین کلمه کد برای هربردار ورودی پیدا گردد. در واقع اندیس نزدیکترین کلمه کد به بردار تعیین می گردد.البته باید این نکته را در نظر داشت که اندازه کلمه کد از تصویر اصلی خیلی کوچک تر می باشد، که هدف فشرده سازی تصویر می باشد. در فرآیند کدگشایی نیز تصویر توسط کتاب کد مربوطه اش بازیابی می شود.کدگشایی زمانی تکمیل می گردد که تصویر به طور کامل بازیابی گردد. روشهای چندی سازی بردار یبه دو دسته کلاسیک و ممتاهیورستیک تقسیم بندی می گردد. چندی سازی با ساختار درختی، چندی سازی برداری حاصل ضربی و lbg از روشهای کلاسیک هستند.چندی سازی متاهیورستیک شامل الگوریتم های تکاملی و هوش جمعی مانند ژنتیک، بهینه سازی ازدحام ذرات و کرم شب تاب و غیره می باشد.
کوآنتیزه سازی تصاویر(quantization)
در کوانتیزه سازی تصاویر سطوح نامحدود(پیوسته) شدت روشنایی را به یک محدوده گسسته تبدیل می کنیم. به عبارت دیگر در ابتدا تعداد سطوح روشنایی را کم می کنیم و سپس تصویر را نمایش می دهیم. این روش از ضعف چشم انسان که نمی تواند همه رنگهای واقعی راببیند استفاده کرده است در واقع چشم انسان نمی تواند بین رنگ های خیلی نزدیک به هم تفوت قائل شود. بنابراین لازم نیست همه رنگها نشان دهیم. به منظور حذف رنگهای خیلی شبیه از کوانتیزه سازی استفاده می کنیم. در این روش در واقع بازه ای از رنگه های مشابه را با یک رنگ نشان می دهیم و به این ترتیب تعدادسطوح شده روشنایی را کم می کنیم. هر چه تعداد سطوح روشنایی بیشتر باشد، تصویر نشان داده شده واقعی تر به نظر می رسد و هر چه کمتر باشد تصویر به سمت سیاه وسفید نزدیک خواهد شد.
تعاریف یادگیری ماشین
آرتور ساموئل (1959)
یک حوزه مطالعاتی که به ماشین ها توانایی یادگیری می دهد، بدون این که نیازباشد این ماشین ها به طور صریح برنامه نویسی شوند.
تام میشل(1998)
با داشتن یک وظیفه مانند T و یک معیار کارایی مانند P، می گویی یک برنامه کامپیوتری از تجربه ی E یاد می گیرد اگر معیار کارایی آن برنامه یعنی P برای انجتم وظیفه T با استفاده از تجربه E بهبود یابد.
مثال : بازی چکرز
وظیفه : انجام بازی چکرز
تجربه : هزاران هزار بار بازی در مقابل خود
معیار کارایی تعداد دفعات برد در برابر رقبای جدید
انواع روشهای یادگیری
1. یادگیری نظارت شده : پاسخ درست را برای چند نمونه محدود از ورودی ها را به ماشین می دهیم به امید آنکه بتواند آن را به نمونه های دیگر تعمیم دهد.
2. یادگیری تقویتی : در این روش به ماشین گفته می شود که پاسخش تا چه اندازه درست می باشد (به طور مثال با دادن امتیاز) و خود ماشین مسئول یافتن پاسخ درست می باشد. کاربرد آن بیشتر در حوزه رباتیک می باشد.
3. یادگیری بدون نظارت : به ماشین هیچ اطلاعاتی در مورد پاسخ درست نمی دهیم و تنها از ماشین خواسته می شود ورودی هایی که دارای وجوه مشترک هستند را پیدا کند.
یادگیری نظارت شده
ورودی : یک مجموعه آموزشی می باشد که در آن به ازای هر ورودی پاسخ درست داده شده است.
{(x (1), y (1)), (x (2), y (2)), …, (x (m), y (m))}
که X ها ورودی و yها خروجی به ازای هر x می باشند.
هدف آن یافتن یک مقدار تقریبی مناسب برای نگاشت زیر می باشد:
F: X -> Y
مثال:
تشخیص هرزنامه : دراین مثال ایمیل ها به دو دسته هرزنامه و غیرهرزنامه تقسیم می شوند
تشخص ارقام : مجموعه ای از پیکسل ها به مجموعه اعداد {9،...،2،1، 0 } تخصیص داده می شود
تشخیص سرطان : نگاشت به داده های پزشکی {بدخیم ، خوش خیم}
نکته :
خروجی می تواند پیوسته یا گسسته باشد . به مجموعه گسسته کلاس بندی می گویند(مانند صفر و یک)
مثال : تشخیص ارقام دست نویس
ورودی تصویر یک رقم می باشد و خروجی آن یک رقم می باشد
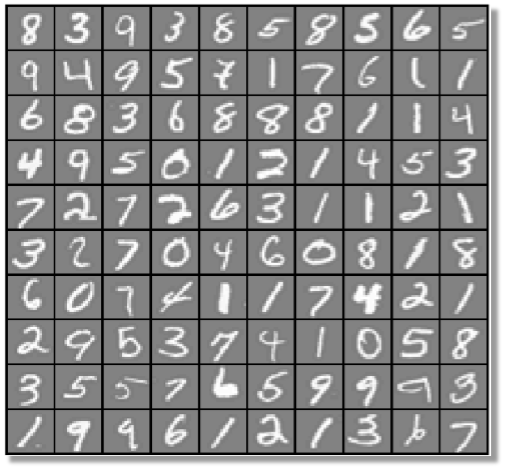
تصویر به صورت n*n در نظر گرفته شده است. در واقع یک تصویر دریافت می کند و رقم آن را تشخیص می دهد.
مثال : قیمت گذاری خانه
ورودی : اندازه خانه (بر حسب فوت مربع)
خروجی : قیمت تخمینی
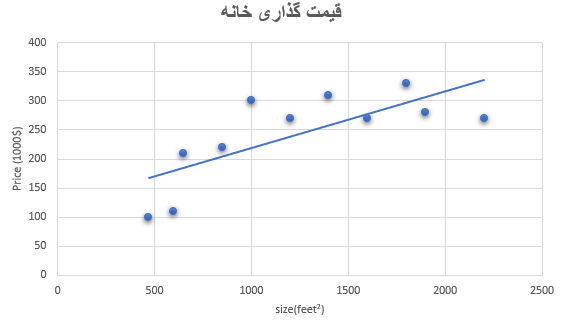
رگرسیون
پیش بینی کمیت هایی با مقادی پیوست می باشد (مانند قیمت خانه)
کلاس بندی
پیش بینی کمیتهایی با مقادیر گسسته (مانند صفر و یک)
رگرسیون
یک نوع مدل آماری می باشد که از آن برای پیش بینی یک مغییر از روی یک یا چند متغییر دیگر استفاده می گردد. اغلب برای کشف مدل رابطه ی خطی بین متغییر ها از رگرسیون(Regression) استفاده می گردد. در این حالت با فرض اینکه یک یا چند متغییر توصیفی که مقدار آن ها مستقل از بقیه متغییرها یا تحت کنترل محقق است و می تواند در پیش بینی متغییر پاسخ که مقدارش وابسته به متغییرهای توصیفی و تحت کنترل محقق نیست وثر واقع شوند.
انواع رگرسیون لجستیک
1. رگرسیون لجستیک باینری یا دو وجهی(Binary logistic regression)
2. رگرسیون لجستیک چند سطحی یا چند وجهی (Multinomial logistic regression)
3. رگرسیون لجستیک ترتیبی (Ordinal logistic regression)
رگرسیون لجستیک دودویی
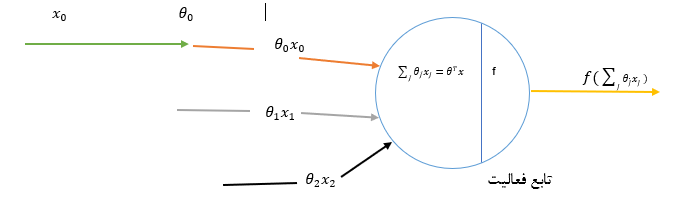
رگرسیون خطی ساده
اگر از یک متغییر مستقل به منظور شناسایی و پیش بینی متغییر وابسته استفاده گردد ، مدل را رگرسیون خطی ساده (Simple Linear Regression) می نامند. که به صورت زیر می باشد
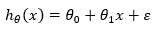
رابطه فوق ، معادله یک خط می باشد که جمله خطا یا همان ε به آن اضافه گردیده است. که در آن ᶿ0 عرض از مبدا و ᶿ1 شیب خط می باشد. شیب خط در حالت ریگرسیون خطی ساده نشان دهنده میزان حساسیت متغییر وابسته به متغییر می باشد. بدین معنی که با افزایش یک واحد متغییر مستقل چه مقدار متغییر وابسته تغییر خواهد کرد. در واقع عرض از مبدا نشان دهنده مقداری از متغییر وابسته می باشد که به ازاء مقدار متغییر مستقل برابر با صفر محاسبه می شود. گاهی مدل رگرسیون را بدون عرض از مبدا در نظر می گیرند و β0 = 0 محسوب می کنند. که این بدین معنی است که با صفر قرار دادن مقدار متغییر مستقل ، مقدار متغییر وابسته نیز باید صفر در نظر گرفته شود.از این گونه مدل زمانی استفاده میگردد که محقق به این نتیجه رسیده باشد که خط رگرسیون باید از مبدا مختصات عبور کند. که به صورت زیر نوشته می گردد:

به دلیل آنکه پیش بینی رابطه بین متغییر وابسته و مستقل به صورت دقیق نیست، جمله خطا را یک متغییر تصادفی با میانگین صفر در نظر گرفته می شود تا این رابطه داری اریبی نباشد.
به این نکته باید توجه کرد رابطه خطی در مدل رگرسیون به
معنی وجود رابطه خطی بین ضرایب است نه بین متغییرهای مستقل. به طور مثال مدل 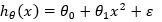 نیز خطی در نظر گرفته می شود در حالیکه
نیز خطی در نظر گرفته می شود در حالیکه 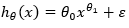 خطی نمی باشد و مدل نمایی می
باشد. همچنین در این مدل فرض شده است که خطا یک جمله تصادفی و تغییرات آن از
متغییر X مستقل می باشد.
در نتیجه مقدار خطا به مقدار متغییر مستقل وابسته نمی باشد. در این روش توسط
معادله خطی که توسط روش رگرسیون معرفی شده است، برآوردی از متغییر وابسته به ازای
متغییرهای مستقل توسط خط رگرسیون بدشت می آید. در واقع سعی می گردد براساس داده
های موجود پارامترها را به طریقی انتخاب کنند که کمترین خطا را داشته باشد. برای
تعریف خطا و حداقل کردن آن روشهای ممختلفی وجود دارد. در رگرسیون خطی از به منظور
کمینه کردن از معیار مربعات خطا استفاده می گردد. از طرفی میانگین مقدارهای خطا
صفر در نظر گرفته شده است، همچنین می دانیم که مجموع مربعات خطا زمانی کمترین
مقدار خود را خواهد داشت که توزیع داده ها نرمال باشند. در نتیجه، یکی از فرضیات
مهم برای مدل رگرسیون خطی ساده نرمال بودن داده های متغییر وابسته یا باقی مانده
ها می باشد.
خطی نمی باشد و مدل نمایی می
باشد. همچنین در این مدل فرض شده است که خطا یک جمله تصادفی و تغییرات آن از
متغییر X مستقل می باشد.
در نتیجه مقدار خطا به مقدار متغییر مستقل وابسته نمی باشد. در این روش توسط
معادله خطی که توسط روش رگرسیون معرفی شده است، برآوردی از متغییر وابسته به ازای
متغییرهای مستقل توسط خط رگرسیون بدشت می آید. در واقع سعی می گردد براساس داده
های موجود پارامترها را به طریقی انتخاب کنند که کمترین خطا را داشته باشد. برای
تعریف خطا و حداقل کردن آن روشهای ممختلفی وجود دارد. در رگرسیون خطی از به منظور
کمینه کردن از معیار مربعات خطا استفاده می گردد. از طرفی میانگین مقدارهای خطا
صفر در نظر گرفته شده است، همچنین می دانیم که مجموع مربعات خطا زمانی کمترین
مقدار خود را خواهد داشت که توزیع داده ها نرمال باشند. در نتیجه، یکی از فرضیات
مهم برای مدل رگرسیون خطی ساده نرمال بودن داده های متغییر وابسته یا باقی مانده
ها می باشد.
تابع هزینه
پارامترها را به گونه ای انتخاب می کنیم که به ازای هر
نمونه آموزشی مانند (x,y)، مقدار 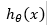 تا حد ممکن به مقدار y نزدیک
باشد.
تا حد ممکن به مقدار y نزدیک
باشد.

تابع هزینه برابر است با مجموع مربعات خطا
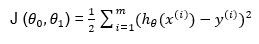
در واقع باید طوری
انتخاب کنیم که مقدار این تابع مینیمم گردد.
یکی از مهمترین الگوریتمهای محاسبه تابع هزینه تابع گرادیان کاهشی می باشد
گرادیان کاهشی
در این روش به صورت زیر عمل می کنیم
- یک مقدار تصادفی به پارامترهای
- مقدار پارامترها را به گونه ای تغییر می دهیم که مقدار تابع هزینه
کاهش یابد.
- مرحله 2 را آنقدر تکرار می کنیم تا به یک مقدار کمینه برای تابع هزینه برسیم.
گرادیان کاهشی به صورت بهینه سراسری و محلی می باشد و تضمین نمی کند که همیشه بهینه سراسری را پیدا کند ولی حتما بهینه محلی را پیدا می کند.
گرادیان یک تابع جهتی می باشد که در آن جهت تابع بیشترین افزایش (شیب) را دارا می باشد.
بنابراین باید در خلاف جهت بردار گرادیان حرکت کرد تا بیشترین کاهش را داشته باشیم.
نکته : به روزرسانی پارامترها باید به صورت ترتیبی انجام نشود بلکه باید همزمان انجام شوند
اگر نرخ یادگیری خیلی کوچک باشد گرادیان کاهشی به کندی همگرا می گردد. و اگر خیلی بزرگ باشد واگرایی اتفاق می افتد.
انواع گرادیان کاهشی
1. گرادیان کاهشی با دسته های کامل : در هر تکرار الگوریتم، از تمام نمونه های آموزشی بره منظور به روزرسانی مقدار پارامترها استفاده می گردد. عیب آن این است که برای داده های زیاد زمان بر می باشد و کارا نمی باشد.
2. گرادیان کاهشی اتفاقی(آنلاین) : در هر تکراربروزرسانی از یک داده تصادفی استفاده می شود
3. گرادیان کاهشی با دسته های کوچک: در هر تکرار به روزرسانی از یک دسته کوچک تصادفی از نمونه ها استفاده می گردد.
کاربرد گرادیان کاهشی در رگرسیون خطی
حال در فورمول گرادیان کاهشی به تابع
حال از طرفین نسبت به تمام پارامترها مشتق می گیریم
نکته : باید به صورت همزمان انجام شوند
در رگرسیون خطی تابع هزینه یک تابع کوژ می باشد و در نتیجه گرادیان کاهشی در صورت همگرایی لزوما در بهینه ی سراسری همگرا می گردد
رگرسیون خطی چند متغیره
یکی از روشهای رایج در تحلیل چند متغیره تکنیگ ریگرسیون چندگانه(Multiple Linear Regression) می باشد. بر اساس
تحلیل رگرسیونی، یک رابطه خطی بین «متغیر پاسخ» (Response Variable) با یک یا چند «متغیر توصیفی (Explanatory Variable) » برقرار میشود. در صورتی که در مدل رگرسیون چند متغییر توصیفی یا مستقل به کهر گرفته شود به آن رگرسیون چندگانه گفته می شود و در آن بیش از یک متغییر پاسخ مورد تحلیل و مدلسازی قرار می گیرد.و از آن در بسیاری از شاخه های علوم بخصوص فیزیک و شیمی استفاده می گردد و همچنین برای پیشگویی داده های مالی از رگرسیون چندگانه استفاده می گردد. در واقع به صورت زیر می باشد.
برای سادگی می توانیم مقدار x0 =1 را نیز اضافه کنیم
حال باید مقدار بهینه پارامترها را به دست آوریم.
حال مانند روش توضیح داده شده در بالا مقدار پارامترها را به دست می آوریم.
رگرسیون چندجمله ای
در واقع درجه چندجمله ای بیشتر از یک می باشد یعنی به صورت زیر
رگرسیون لجستیک(دسته بندی)
معمولا به منظور بیان رابطه خطی بین دو متغییر کمی از ضریب همبستگی استفاده می کنیم. مدل رابطه بین آنها از طریق مدل رگرسیون رسم می کنیم. در این میان یک الگو برای پیشبینی متغیر وابسته (Y) براساس متغیر مستقل (X) ایجاد میشود. در این مدل هر دو متغییر وابسته و مستقل، کمی هستند. اگربخواهیم رابطه بین یک متغیر مستقل (با مقدارهای پیوسته) را با یک متغیر وابسته با مقدارهای کیفی بسنجیم. در این حالت روش عادی رگرسیون خطی جوابگو نخواهد بود و باید از «رگرسیون لجستیک» (Logistic Regression) استفاده کنیم. این روش در واقع یکی از روشهای دسته بندی(Classification) می باشد. در این روش رگرسیونی، از مفهوم و شیوه محاسبه «نسبت بخت» (Odds Ratio) استفاده میگردد. این همان رگرسیون با یک آستانه می باشد.
در رگرسیون داریم :
در واقع خروجی بین
تا
می تواند باشد. اگر بتوانیم تغییری در آن دهیم که به صورت زیر دربیاید تبدیل به رگرسیون لجستیک می شود که در این حالت دسته بندی انجام می شود.
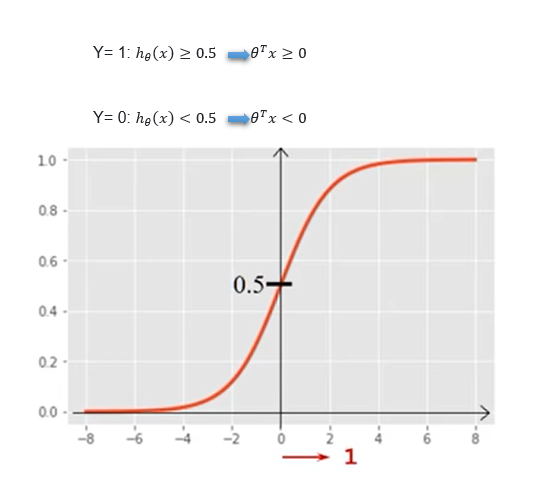
در این حالت از تابع لجستیک یا سیگموید استفاده می کنیم
شکل تابع آن به صورت زیر می باشد
نکته :
سگموید به معنای شبیه به حرف S می باشد و بدلیل آنکه این تابع شبیه به حرف S می باشد به آن تابع سیگموید می گویند.
نکته :
مقدار آستانه در تابع سیگموید 0.5 می باشد. و داده های پرت نیز روی تاثیر زیادی نمی گذارند.
حال یک کلاس با دو مقدار 0 و 1 رادر نظر می گیریم واحتمال تابع را به صورت زیر بیان می کنیم
به طور مثال اگر
باشد این بدان معنی می باشد که به احتمال 70 درصد متعلق به کلاس 1 و به احتمال 30درصد متعلق به کلاس 0 می باشد.
حال دو فورمول فوق را ترکیب می کنیم
با استفاده از تابع درستنمایی و حداکثر سازی آن میتوان مدل را براساس برآورد پارامترها بدست آورد
حال یک تابع درست نمایی تعریف می کنیم
باید مقدار آن ماکزیمم شود یعنی هر یک از داده ها ماکزیمم گردد و به عبارت دیگر مقدار
طوری به دست آوریم که مقدار تک تک داده ها حداکثر گردد.
حال از آن لگاریتم می گیریم
تابع هزینه
مرز تصمیم گیری در الگوریتم ریگرسیون لجستیک
در واقع یک آستانه بر روی خروجی دسته بند قرار می دهیم
نکته : از آنجا که
یک تابع غیر خطی از پارامترها می باشد، تابه هزینه آن دیگر تابع کوژ نخواهد بود و نمی توانیم از روش گرادیان کاهشی برای محاسبه تابع هزینه استفاده کنیم
تابع هزینه رابه صورت زیر تعریف می کنیم :
حال دو تابع فوق را با یکدیگر ترکیب می کنیم :
حال آن را مینیمایز می کنیم تا بتوانیم مقدار پارامترها را به دست بیاوریم چون تابع کوژ می باشد بنابراین محدب می باشد و می توان آن را با گرادیان کاهشی مینیمایز کرد.
نکته :
این الگوریتم درست مانند الگوریتم رگرسیون خطی می باشد و تنها تفاوت آن در تابع فرضیه می باشد.
رگرسیون لجستیک چند دسته ای (چند کلاسی)
همانطور که قبلا گفته شد یادگیری نظارت شده دارای دو دسته می باشد یکی پیوسته(رگرسیون) ودیگری گسسته (دسته بندی) می باشد. رگرسیون لجستیک جزء گروه دسته بندی می باشد. رگرسیون لجستیک گاهی بیشتر از دو کلاس دارد که به آن رگرسیون لجستیک چند دسته ای می گویند.
یک مثال برای دسته بندی
در ایمیل ممکن است ایمیل کاری، خانوادگی یا سرگرمی و غیره باشد. در واقع بیشتر از 2 تا می باشد.
در حالت کلی داریم
Y
{1, 2, 3, …, k}
در ابتدا آن را تبدیل به چند عدد دسته بندی دودویی می کنیم. یکی از دسته را انتخاب کرده و هر کلاسی غیر از این کلاس را تحت عنوان یک کلاس دیگر انتخاب می کنیم و این کار را برای هر کلاس تکرار می کنیم مثلا یک کلاس سه کلاسه را تبدیل به 3 تا مسئله کلاس بندی 2 کلاسه می کنیم. و یک مسئله k کلاسه تبدیل به k مسئله دو کلاسه می شود.
که به آن روش one versus one (یکی در برابر همه) گفته می شود. مقدار خروجی مکزیمم مقادیر خروجی می باشد.
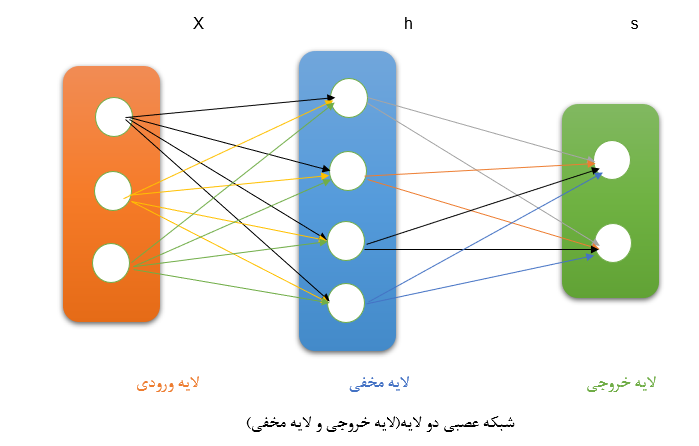
شبکه های عصبی
مغز انسان دارای تعداد بسیار زیادی نورون می باشد تا به کمک آنها اطلاعات مختلف را پردازش کند و جهان اطراف را بشناسد. به عبارتی دیگر، نورون ها در مغز انسان به کمک دندرویدها از نورون های دیگر اطلاعات را دریافت می کنند. آنها اطلاعات دریافت شده را با هم جمع می کنند و اگر از یک حد آستانه ای فراتر رود به اصطلاح فعال (Fire) می شوند. و این سیگنال فعال شده توسط آکسون ها به نورون های دیگر متصل می شود. در علوم کامپیوتر و هوش مصنوعی از نورون های مغز برای ساخت الگوریتمی به نام شبکه های عصبی مصنوعی(Artificial Neural Network)استفاده می گردد. بوسیله این الگوریتم می توان مدل های مختلف و پیچیده ای را می توان شناخت. به طور مثال طبقه بندی هایی بادقت خوب می توان انجام داد یا خوسه بندی هایی بر روی داده های بزرگ انجام دهیم.
نکته :
شبکه های عصبی می توانند با ترکیب ویژگی های سطح پایین، ویژگی های سطح بالای مورد نیاز خود را یاد بگیرند.
هر تعداد لایه مخفی نیاز باشد می توان اضافه کرد.
دسته بندی خطی
s=wx+b
شبکه عصبی دو لایه
h= f(W1 x+b1)
S = w2 h +b2
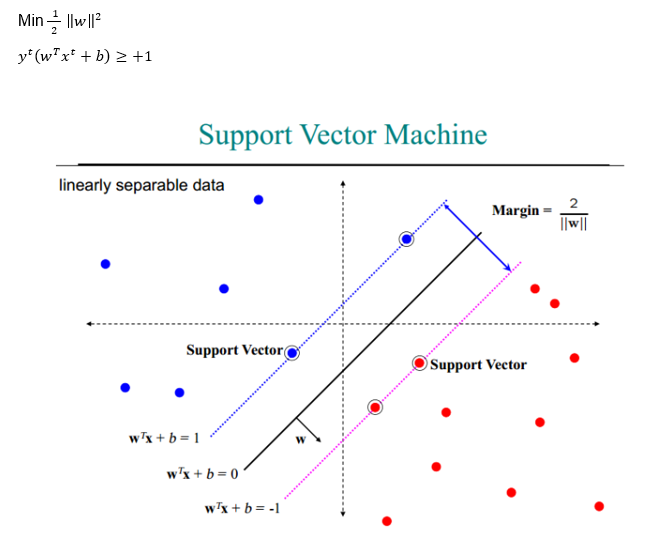
ماشین های بردار پشتیبان(Support Vector Machine(SVM))
الگوریتم SVM یکی از رایج ترین روشها در حوزه دسته بندی داده ها می باشد البته فقط برای دسته بندی استفاده نمی شوند بلکه برای رگرسیون و یادگیری بدون نظارت هم استفاده می گردند . بخصوص رشته های دیگر به دلیل استفاده راحت، آن را زیاد بکار می برند. این الگوریتم متعلق به آقای وپنیک و همکارانش (1992) می باشد که اولین بار در سال 1963 ارائه گردید ولی در بازه زمانی 1963 تا 1992 زیاد محبوب و پرطرفدار نبوده است زیرا فقط برای مسائل خطی استفاده می گردید در سال 1992 آقای وپنیک در آن تغییراتی ایجاد کرد و ترفند کرنل در آن استفاده کرد و از آن در مسائل غبر خطی هم استفاده کرد
بردارهای پشتیبان و ماشین بردار پشتیبان
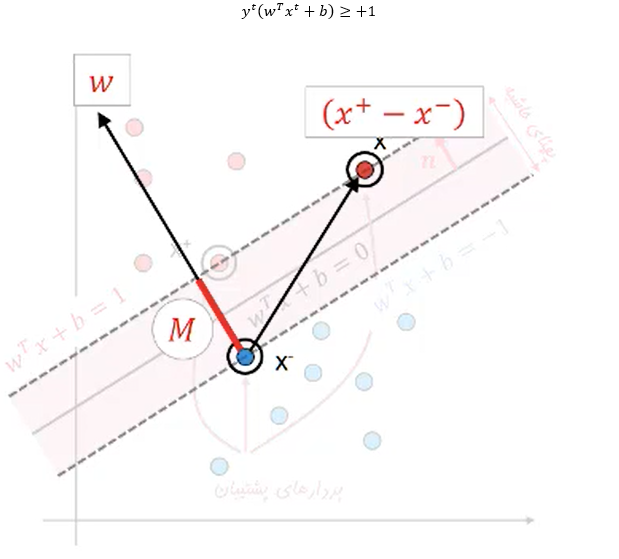
بردارهای پشتیبان به مجموعه ای از نقاط در فضای n بعدی اطلاق می شود که مرز دسته ها را مشخص می کنند و با توجه به آنکه مرزبندی و دسته بندی داده ها بر اساس آنها انجام می شود با جابجایی حتی یکی از آنها ممکن است خروجی تغییر کند. در واقع SVM فقط داده های بردار پشتیبان را مبنای یادگیری و ساخت مدل قرار می دهد و نسبت به دیگر نقاط داده حساس نمی باشد و هدف آن پیدا کردن بهترین مرز در بین داده ها می باشد بطوری که بیشترین فاصله(margin) ممکن را از تمام دسته ها(بردار پشتیبان آنها) داشته باشد زیرا موجب بیشترین پایداری در برابر تخریب داده ها می گردد(افزایش قابلیت تعمیم).
معادله مرز جداکننده را به صورت زیر می نویسیم
که در آن
یک بردار و b یک عدد (بایاس) می باشد.
نمونه های آموزشی
حال باید بردار w و مقدار b را به گونه ای پیدا کنیم که :
حال دو معادله را ترکیب می کنیم
می دانیم
حال دو معادله را از هم کم می کنیم
بنابراین برای اینکه M ماکزیمم شود باید||w|| مینیمم گردد ولی باید کلاس بندی را نیز درست انجام دهد.
به این دلیل ||w|| را به توان 2 رساندیم که این یک تابع محدب گردد زیرا بهینه سازی آن آسان می باشد
الگوریتم های تکاملی در سال 1970 توسط John Holland معرفی گردید.
ایده کلی الگوریتم های تکاملی
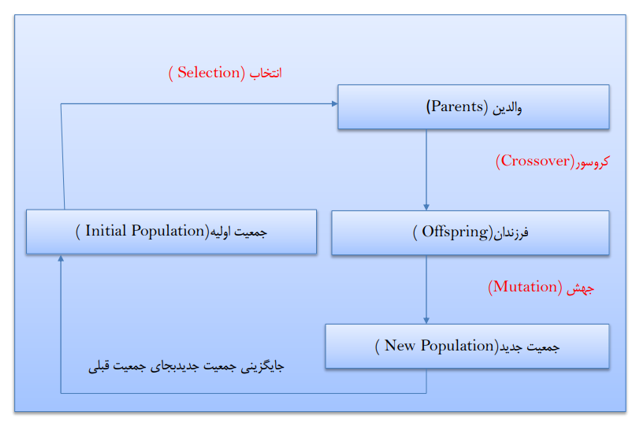
الگوریتم های تکاملی، مجموعه بسیار بزرگی از راه حلهای ممکن را جهت حل یک مسئله تولید می کنند. در مرحله بعد هر یک از این راه حلهای تولید شده توسط یک تابع تناسب (Fitness Function) مورد ارزیابی قرار می گیرد. سپس تعدادی از بهترین راه حلها خود باعث تولید راه حلهای جدیدتری می شوند که این عمل سبب تکامل راه حلها می گردد. درنتیجه ، فضای جستجو به سمتی تکامل پیدا می کند که به راه حل مطلوب برسد. در صورتی که پارامترها به صورت صحیح انتخاب شوند می توانند به صورت موثر عمل کنند.
الگوریتم ژنتیک
الگوریتم ژنتیک نوع خاصی از الگوریتمهای تکاملی(Evolutionary Algorithms)، دسته ای از روش های یادگیری بر پایه تکامل بیولوژیک است که از تکنیکهای زیستشناسی فرگشتی مانند وراثت، جهش زیستشناسی و اصول انتخابی داروین برای یافتن فرمول بهینه جهت پیشبینی یا تطبیق الگو استفاده میشود. الگوریتمهای ژنتیک اغلب گزینه خوبی برای تکنیکهای پیشبینی بر مبنای رگرسیون هستند. در مدلسازی الگوریتم ژنتیک یک تکنیک برنامهنویسی است که از تکامل ژنتیکی به عنوان یک الگوی حل مسئله استفاده میکند. مسئلهای که باید حل شود دارای ورودیهایی میباشد که طی یک فرایند الگوبرداری شده از تکامل ژنتیکی به راهحلها تبدیل میشود سپس راه حلها به عنوان کاندیداها توسط تابع ارزیاب (Fitness (Function مورد ارزیابی قرار میگیرند و چنانچه شرط خروج مسئله فراهم شده باشد الگوریتم خاتمه مییابد. بهطور کلی یک الگوریتم مبتنی بر تکرار است که اغلب بخشهای آن به صورت فرایندهای تصادفی انتخاب میشوند که این الگوریتمها از بخشهای تابع برازش، نمایش، انتخاب وتغییر تشکیل میشوند.
جدول هم ارزی مفاهیم بیولوژیکی و عناصر GA
نمودار گردشی فرآیند یک الگوریتم تکاملی
فرایند تولید تا زمانی که جواب مورد نظر به دست آید ادامه می یابد(اغلب جمعیت بصورت تصادفی تولید می شود)
ساختار الگوریتم های ژنتیک
هوش جمعی
نحوه ارتباط و همکاری حشرات اجتماعی نظیر مورچه ها، زنبورها و موریانه ها و همچنین عملکرد حیوانات جمعی مانند پرندگان و ماهی ها و بعضی شکارچی ها نمونه هایی از هوش جمعی هستند. به طور مثال رفتار جمعی ماهی ها را بررسی می کنیم این ماهی ها به صورت جمعی حرکت می کنند و اگر خطری از طریق یک شکارچی آنها را تهدید کند به دو یا سه دسته تقسیم می شوند و این عمل سبب می گردد که میزان تلفات حداقل یا صفر گردد زیرا شکارچی در آن واحد نمی تواند همه گروهها را دنبال کند بنابراین اگر بتواند تصمیم بگیرد فقط می تواند یک گروه را دنبال کند و گاهی وقت ها هم بی خیال آنها می شود و می رود و بعد از رفع خطر دوباره جمع می شوند آنها این کار را برای کاهش تلفات انجام می دهند در واقع حواس شکارچی را پرت می کنند و در واقع این کار را بوسیله با هم بودن انجام می دهند این عمل در واقع همان هوش جمعی می باشد.
الگوریتم بهینهسازی ازدحام ذرات (PSO)
این الگوریتم توسط دو دانشمند به نام های جیمز کندی(Kennedy) و راسل ابرهارت(Eberhart) در سال 1995 معرفی گردید. این الگوریتم بر پایه رفتارهای ازدحامی (Swarm Behaviors) گونه های خاصی از موجودات زنده مانند رفتارهای اجتماعی پرواز پرندگان برای یافتن غذا یا حرکت گروهی و در جهت یکسان ماهی ها الهام گرفته شده است. به چنین رفتاری در موجودات زنده، که الهام بخش توسعه برخی از الگوریتم های بهینه سازی معروف می باشند، هوش ازدحامی (Swarm intelligence) گفته می شود. این الگوریتم در واقع یک الگوریتم فرااکتشافی(Meta-Heuristics)می باشد و همچنین بعضی ها آنرا جزء الگوریتم های تکاملی می دانند زیرا یک مکانیزم تکاملی دائما تکرار می شود.و اصل و اساس آن بر پایه به اشتراک گذاری اطلاعات و تجربیات می باشد
الگوریتم PSO دارای تعدادی موجودات زنده به نام ذره می باشد که در فضای جستجو پخش شده اند. هر ذره مقدار تابع هدف را در موقعیتی از فضایی که در آن قرار گرفته را محاسبه می کند. سپس با ترکیب اطلاعات محل فعلیش و بهترین محل که قبلا در آن بوده است و همچنین اطلاعات یک یا چند ذره از بهترین ذرات موجود در جمع ، جهتی را برای حرکت انتخاب می کند. یک مرحله از الگوریتم پس از انجام حرکت جمعی به پایان می رسد. مراحل فوق چندین بار تکرار می گردد تا آنکه جواب مورد نظر به دست آید.
موقعیت : xi
سرعت : yi
بهترین موقعیت تجربه شده : xi ,best
در واقع بردار سرعت جدید مجموع ضریبی از بردار سرعت قدیم (فعلی)، ضریبی از بردار بهترین موقعیت ثبت شده همان ذره و ضریبی از بردار بهترین ذره می باشد البته باید بعد از هر محسابه بررسی شود که آیا نقطه جدید به دست آمده می تواند جایگزین xi ,best و xgbest بشود یا خیر. حال موقعیت جدید می شود موقعیت فعلی به اضافه سرعت جدید. همه ذرات نیز از این قانون پیروی می کنند. گاهی مواقع به بهترین ذره در جمعیت موجود از بهترین ذره در همسایگی(xnbest) استفاده می کنند.
منابع
https://www.youtube.com/watch?v=kgwDP35InuQ&list=PLW529xl11jnnupZKT5Og4pwHPoRFQRQz
https://www.youtube.com/watch?v=MqzM9ZaZRc8
https://wp.kntu.ac.ir/setak/files/Genetic_algorithm.pdf